Recovering Quality After Quantization: PTQ vs. QAT
Recovering Quality After Quantization: PTQ vs. QAT
Quantization is one of the most practical ways to make AI models faster, smaller, and cheaper to deploy. By reducing numerical precision, for example from FP32 to INT8 or lower, teams can reduce memory footprint, improve inference latency, and unlock deployment on more constrained hardware.
But quantization comes with a tradeoff: model quality can drop.
The key question is not just how do we quantize a model? It is:
How do we recover quality after quantization while keeping the performance gains?
Two of the most common approaches are Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT).
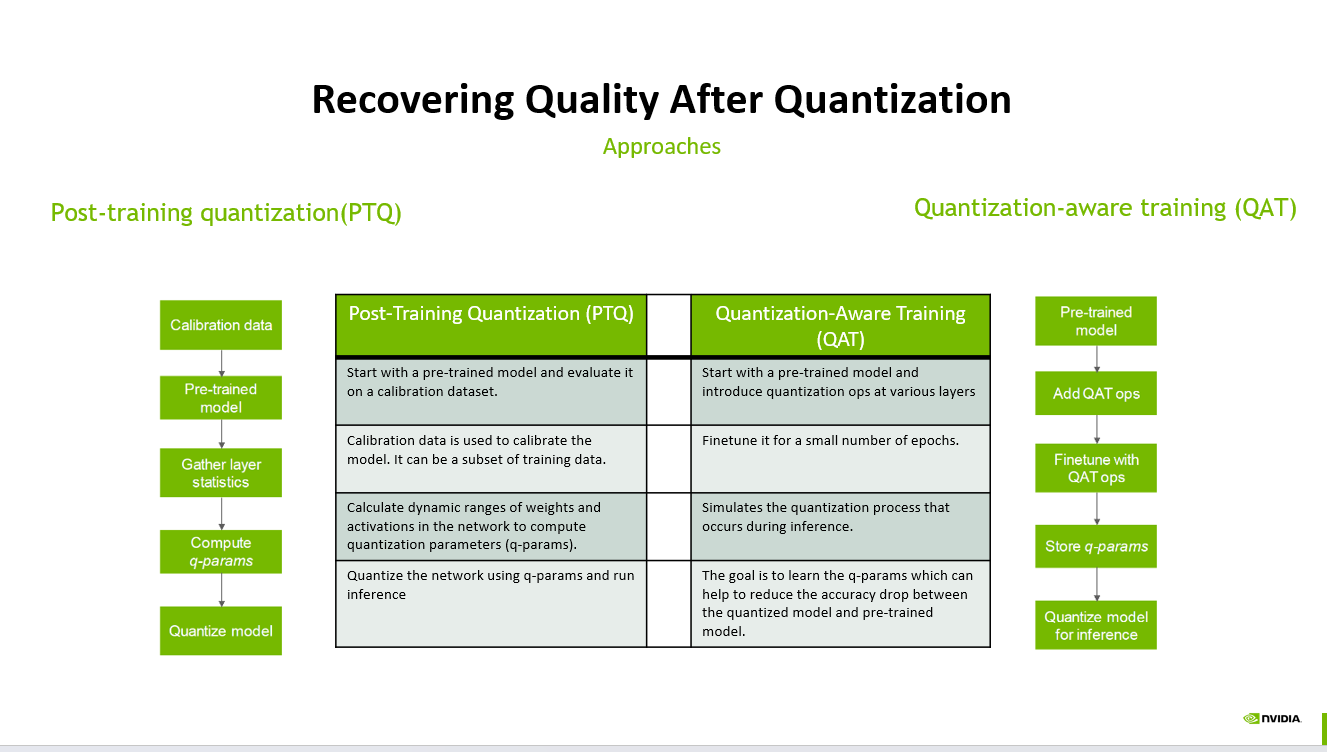
1. Post-Training Quantization (PTQ)
PTQ is usually the faster and simpler path.
The process starts with a pre-trained model. Instead of retraining the model, we use a calibration dataset to observe layer behavior, gather activation and weight statistics, compute quantization parameters, and then quantize the model for inference.
A typical PTQ flow looks like this:
Start with a pre-trained model
Run calibration data through the model
Try Live Demo →Try Live →Hear it before you finish reading
Talk to a live CallSphere AI voice agent in your browser — 60 seconds, no signup.
Gather layer statistics
Compute quantization parameters, or q-params
Quantize the model and run inference
PTQ works well when the model is already robust to reduced precision, the calibration dataset is representative, and the target accuracy tolerance is not extremely strict.
It is especially useful when teams need a fast deployment path with minimal training cost.
However, PTQ can struggle when a model has sensitive layers, outlier activations, or workloads where small numerical changes create noticeable quality degradation.
2. Quantization-Aware Training (QAT)
QAT is more involved, but it often provides better quality recovery.
Instead of quantizing only after training, QAT introduces quantization operations during fine-tuning. The model learns while simulating the effects of quantization, allowing weights and activations to adapt before final deployment.
A typical QAT flow looks like this:
Start with a pre-trained model
Add quantization-aware operations
Fine-tune the model with simulated quantization effects
Store learned quantization parameters
Still reading? Stop comparing — try CallSphere live.
CallSphere ships complete AI voice agents per industry — 14 tools for healthcare, 10 agents for real estate, 4 specialists for salons. See how it actually handles a call before you book a demo.
Quantize the model for inference
The goal is to reduce the accuracy gap between the original pre-trained model and the quantized model.
QAT is often the better choice when quality requirements are strict, quantization is aggressive, or PTQ does not preserve enough accuracy.
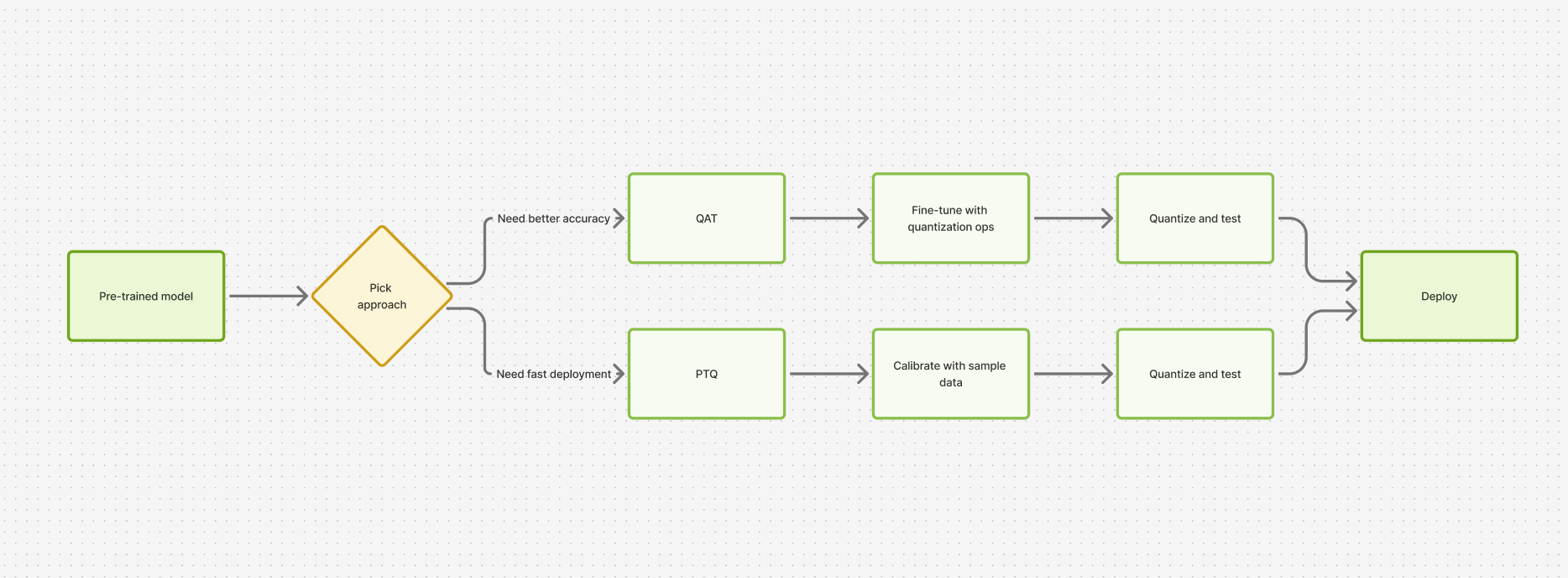
PTQ vs. QAT: How to Choose
The decision usually comes down to the tradeoff between speed, cost, and accuracy.
Use PTQ when you need a fast optimization path, have limited training resources, and can tolerate a small quality drop.
Use QAT when accuracy is critical, the model is sensitive to quantization, or you are targeting lower precision where post-training methods are not enough.
In practice, many teams start with PTQ because it is simpler and cheaper. If quality loss is too high, they move to QAT.
Why This Matters
As AI workloads move from experimentation to production, inference efficiency becomes just as important as model quality.
Quantization helps make models deployable at scale, but quality recovery is what makes quantization production-ready.
The best approach is rarely one-size-fits-all. It depends on the model architecture, calibration data, hardware target, latency requirements, and acceptable accuracy tradeoff.
A good deployment strategy usually follows this pattern:
Start simple with PTQ. Measure quality carefully. Move to QAT when the accuracy gap matters.
That balance is where real-world model optimization happens.
#AI #MachineLearning #DeepLearning #Quantization #ModelOptimization #InferenceOptimization #EdgeAI #MLOps #AIEfficiency #NeuralNetworks #PTQ #QAT #GenerativeAI #LLMOptimization #AIEngineering
## Recovering Quality After Quantization: PTQ vs. QAT — operator perspective Reading Recovering Quality After Quantization: PTQ vs. QAT as an operator, the question isn't 'is this exciting?' — it's 'does this change anything in my agent loop, my prompt cache, or my cost per session?' For an SMB call-automation operator the cost of chasing every new release is real — re-baselining evals, re-pricing per-session economics, retraining the on-call team. The ones that ship adopt slowly and on purpose. ## Where a junior engineer should actually start If you're new to agentic AI and want to be useful in three weeks, skip the framework war and start with one stack: the OpenAI Agents SDK. Build a single-agent app that does one thing well (book an appointment, qualify a lead, escalate a complaint). Then add a second specialist agent with an explicit handoff — the receiving agent gets a structured payload (intent, entities, prior tool results), not a transcript. That's the moment the abstractions click. From there, the next two skills that compound are evals (write the regression case the moment you find a bug, and refuse to merge anything that fails the suite) and observability (log the tool-call graph, not just the final answer). Frameworks come and go; those two habits transfer. Once you've shipped that first multi-agent app end-to-end, the rest of the agentic AI literature reads differently — you can tell which papers are solving real production problems and which are solving demo problems. ## FAQs **Q: Why isn't recovering Quality After Quantization an automatic upgrade for a live call agent?** A: Most of the time it doesn't, and that's the right starting assumption. The relevant test is whether it improves at least one of: p95 first-token latency, tool-call argument accuracy on noisy inputs, multi-turn handoff stability, or per-session cost. Healthcare deployments use 14 vertical-specific tools alongside post-call sentiment scoring and lead-quality classification. **Q: How do you sanity-check recovering Quality After Quantization before pinning the model version?** A: The eval gate is unsentimental — a regression suite that simulates real call traffic (noisy ASR, partial inputs, tool-call timeouts) measures four numbers, and a candidate has to win on three of four without losing badly on the fourth. Anything else is treated as a blog post, not a stack change. **Q: Where does recovering Quality After Quantization fit in CallSphere's 37-agent setup?** A: In a CallSphere deployment, new model and API capabilities land first in the post-call analytics pipeline (lower stakes, async, easy to roll back) and only later in the live realtime path. Today the verticals most likely to absorb new capability first are Real Estate and Salon, which already run the largest share of production traffic. ## See it live Want to see healthcare agents handle real traffic? Walk through https://healthcare.callsphere.tech or grab 20 minutes with the founder: https://calendly.com/sagar-callsphere/new-meeting.Try CallSphere AI Voice Agents
See how AI voice agents work for your industry. Live demo available -- no signup required.