What Does It Mean to “Use Less Bits” in AI?
What Does It Mean to “Use Less Bits” in AI?
In AI, we often talk about making models faster, cheaper, and easier to deploy.
One of the most important techniques behind that is quantization.
At a high level, quantization means representing numbers with fewer bits.
Instead of storing every model weight or activation in high precision, such as FP16 or BF16, we compress those values into lower-precision formats like FP8, INT8, INT4, or even smaller representations.
That sounds simple, but it has a massive impact.
Why bits matter
Modern AI models are built on billions, and sometimes trillions, of numbers.
Every parameter in a neural network is stored as a numerical value. During inference and training, the model also produces intermediate numerical values called activations.
The more bits we use to store each number, the more memory we need.
For example:
FP16 uses 16 bits per value
FP8 uses 8 bits per value
INT4 uses 4 bits per value
So moving from FP16 to FP8 can roughly cut memory usage for those values in half.
Moving from FP16 to INT4 can reduce it even further.
This matters because memory is one of the biggest bottlenecks in AI systems.
Quantization is not just compression
Quantization is not only about making models smaller.
It also helps with:
Faster inference
Try Live Demo →Try Live →Hear it before you finish reading
Talk to a live CallSphere AI voice agent in your browser — 60 seconds, no signup.
Lower latency
Reduced GPU memory usage
Lower serving costs
Better deployment on edge devices
Improved throughput for production systems
For companies deploying large language models, this can directly affect cost, scalability, and user experience.
A smaller model representation can mean serving more requests on the same hardware.
That is why quantization has become such an important part of modern AI infrastructure.
The tradeoff
Using fewer bits also means losing some precision.
A number stored in FP16 can represent values more finely than the same number stored in FP8 or INT4.
So the key question becomes:
How much precision can we remove before model quality starts to degrade?
That is the central challenge of quantization.
If done poorly, quantization can reduce accuracy, hurt reasoning quality, or make outputs unstable.
If done well, it can dramatically improve efficiency while preserving most of the model’s performance.
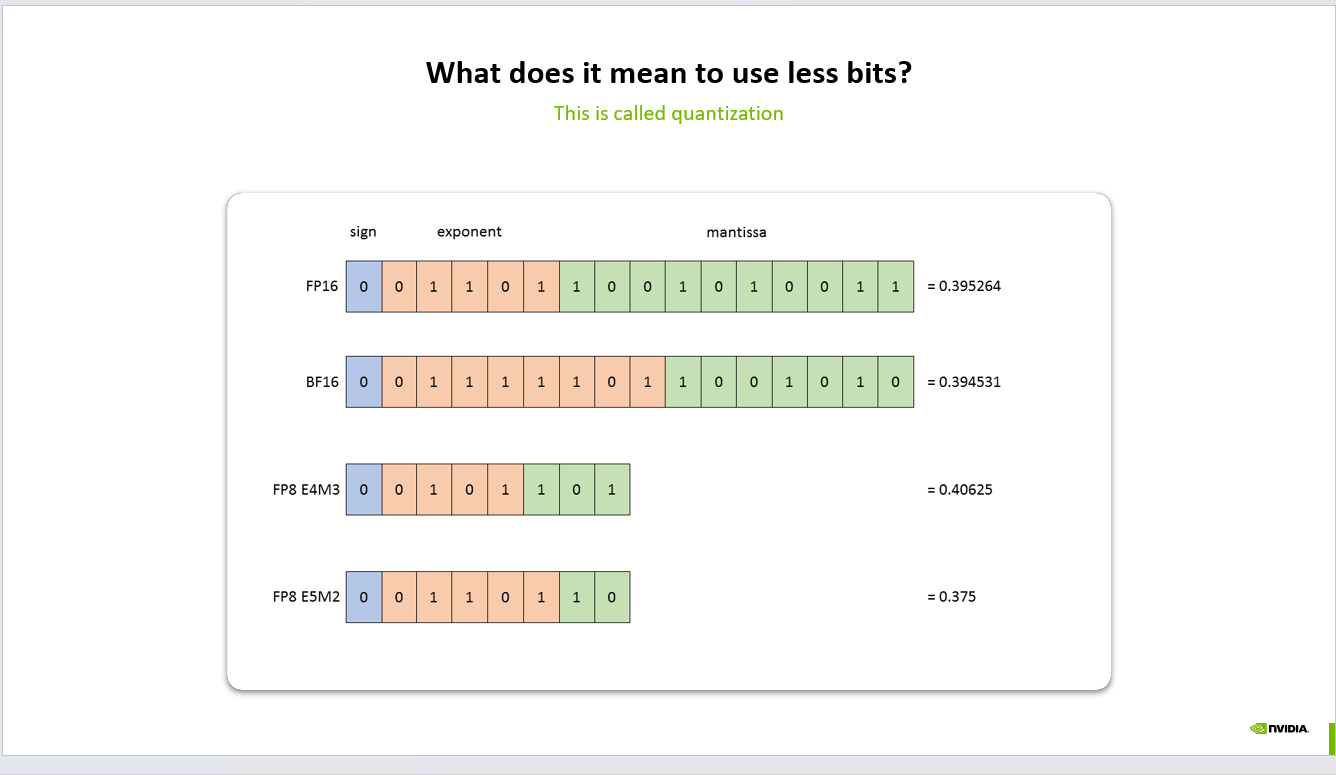
FP16, BF16, and FP8
The image shows different floating-point formats:
FP16 uses 1 sign bit, exponent bits, and mantissa bits
BF16 keeps more exponent range but fewer mantissa bits
FP8 E4M3 uses 8 bits with 4 exponent bits and 3 mantissa bits
FP8 E5M2 uses 8 bits with 5 exponent bits and 2 mantissa bits
The sign bit tells whether the number is positive or negative.
The exponent controls the scale or range.
The mantissa controls the precision.
Different formats make different tradeoffs between range and precision.
Still reading? Stop comparing — try CallSphere live.
CallSphere ships complete AI voice agents per industry — 14 tools for healthcare, 10 agents for real estate, 4 specialists for salons. See how it actually handles a call before you book a demo.
For example, FP8 E5M2 has more exponent bits, which gives it a wider range, but fewer mantissa bits, which gives it less precision.
FP8 E4M3 has more mantissa bits, so it can represent values more precisely, but with a smaller range.
This is why choosing a quantization format is not just about reducing size. It is about choosing the right numerical tradeoff for the model and workload.
Why this matters for LLMs
Large language models are expensive because they require huge amounts of memory and compute.
Quantization helps reduce both.
During inference, lower-precision weights can reduce memory bandwidth pressure. This is especially important because many LLM workloads are memory-bound rather than purely compute-bound.
In practical terms, quantization can make it possible to:
Run larger models on smaller GPUs
Serve more users with the same infrastructure
Reduce cost per token
Deploy models closer to users
Make on-device AI more realistic
This is one of the reasons we are seeing so much interest in FP8, INT8, INT4, and mixed-precision inference.
The future is mixed precision
The future of AI efficiency will not be one single format.
It will likely be mixed precision.
Some parts of a model may need higher precision, while other parts can safely use lower precision.
Critical layers may stay in FP16 or BF16.
Less sensitive layers may move to FP8 or INT4.
Activations, weights, and KV cache may each use different numerical formats depending on the deployment goal.
This gives engineers more flexibility to optimize for accuracy, latency, cost, and hardware availability.
Final thought
Using fewer bits sounds like a small technical detail.
But in AI systems, it can determine whether a model is practical to deploy at scale.
Quantization is one of the key techniques that turns powerful models into usable products.
It is where machine learning, systems engineering, and hardware optimization meet.
The next wave of AI will not only be about building bigger models.
It will also be about making them efficient enough to run everywhere.
#AI #ArtificialIntelligence #MachineLearning #DeepLearning #LLM #LargeLanguageModels #Quantization #FP8 #BF16 #FP16 #ModelOptimization #AIInfrastructure #EdgeAI #GenerativeAI #MLOps #GPUComputing #NVIDIA #TechLeadership #AIEfficiency #SystemsEngineering
## What Does It Mean to “Use Less Bits” in AI? — operator perspective Reading What Does It Mean to “Use Less Bits” in AI? as an operator, the question isn't 'is this exciting?' — it's 'does this change anything in my agent loop, my prompt cache, or my cost per session?' For CallSphere — Twilio + OpenAI Realtime + ElevenLabs + NestJS + Prisma + Postgres, 37 agents across 6 verticals — the bar for adopting any new model or API is unsentimental: does it shorten the inner loop on a real call, or just on a benchmark? ## Where a junior engineer should actually start If you're new to agentic AI and want to be useful in three weeks, skip the framework war and start with one stack: the OpenAI Agents SDK. Build a single-agent app that does one thing well (book an appointment, qualify a lead, escalate a complaint). Then add a second specialist agent with an explicit handoff — the receiving agent gets a structured payload (intent, entities, prior tool results), not a transcript. That's the moment the abstractions click. From there, the next two skills that compound are evals (write the regression case the moment you find a bug, and refuse to merge anything that fails the suite) and observability (log the tool-call graph, not just the final answer). Frameworks come and go; those two habits transfer. Once you've shipped that first multi-agent app end-to-end, the rest of the agentic AI literature reads differently — you can tell which papers are solving real production problems and which are solving demo problems. ## FAQs **Q: How does what Does It Mean to “Use Less Bits” in AI? change anything for a production AI voice stack?** A: Most of the time it doesn't, and that's the right starting assumption. The relevant test is whether it improves at least one of: p95 first-token latency, tool-call argument accuracy on noisy inputs, multi-turn handoff stability, or per-session cost. Real Estate deployments run 10 specialist agents with 30 tools, including vision-on-photos for listing intake and follow-up. **Q: What's the eval gate what Does It Mean to “Use Less Bits” in AI? would have to pass at CallSphere?** A: The eval gate is unsentimental — a regression suite that simulates real call traffic (noisy ASR, partial inputs, tool-call timeouts) measures four numbers, and a candidate has to win on three of four without losing badly on the fourth. Anything else is treated as a blog post, not a stack change. **Q: Where would what Does It Mean to “Use Less Bits” in AI? land first in a CallSphere deployment?** A: In a CallSphere deployment, new model and API capabilities land first in the post-call analytics pipeline (lower stakes, async, easy to roll back) and only later in the live realtime path. Today the verticals most likely to absorb new capability first are Real Estate and Healthcare, which already run the largest share of production traffic. ## See it live Want to see healthcare agents handle real traffic? Walk through https://healthcare.callsphere.tech or grab 20 minutes with the founder: https://calendly.com/sagar-callsphere/new-meeting.Try CallSphere AI Voice Agents
See how AI voice agents work for your industry. Live demo available -- no signup required.